CSS
CSS przez lata traktowany był jako brzydkie kaczątko Sieci. Postrzegano go jako niemalże prymitywny język, który służył do stylowania, a równocześnie nie posiadał wielu funkcjonalności uprzyjemniających pracę z nim. Niemniej to się zdecydowanie zmieniło. Obecny CSS coraz bardziej przypomina klasyczne języki programowania, a i powoli przejmuje ficzery dotąd dostępne tylko w narzędziach pokroju Sassa. Pozwoliłem sobie wydestylować kilka nowości, które moim zdaniem mogą najwięcej namieszać w sposobie pisania CSS-a.
Layout
Nowoczesne systemy layoutowe (a zwłaszcza pierwszy z nich, flexbox) były bez wątpienia rozwiązaniami rewolucyjnymi, które na dobre zmieniły sposób, w jaki obecnie pisze się CSS. W końcu osoby webdeveloperskie dostały do rąk narzędzia stworzone wyłącznie do układania treści na stronie – koniec kombinowania z przestarzałym float, pozycjonowaniem czy, o zgrozo, tabelkami! Dzisiaj wszystkie te narzędzia w końcu wykorzystywać można do tego, do czego zostały stworzone, i nie trzeba pocić się, próbując uzyskać jakiś bardziej zaawansowany układ treści na stronie. Ba, co więcej, nowoczesne systemy layoutowe są zdecydowanie prostsze od swoich poprzedników, dzięki czemu naprawdę dobre efekty można uzyskać już w jednej linijce kodu. Pozwalają też na wykorzystanie algorytmicznego podejścia do tworzenia layoutów oraz na zdobycie świętego Graala layoutów bez stracenia resztek włosów na głowie.
Na ten moment mamy do dyspozycji dwa systemy layoutowe: flexbox (starszy) i grid (nowszy). Co oczywiście rodzi oczywiste pytanie, czy jest miejsce dla aż dwóch? Odpowiedź brzmi: tak, jak najbardziej. Główna różnica zasadza się w tym, w jaki sposób podchodzą one do układania strony. Grid jest, cóż, gridem (siatką), więc pozwala układać layout w dwóch osiach równocześnie. Z kolei flexbox pozwala układać layout tylko w jednej osi:
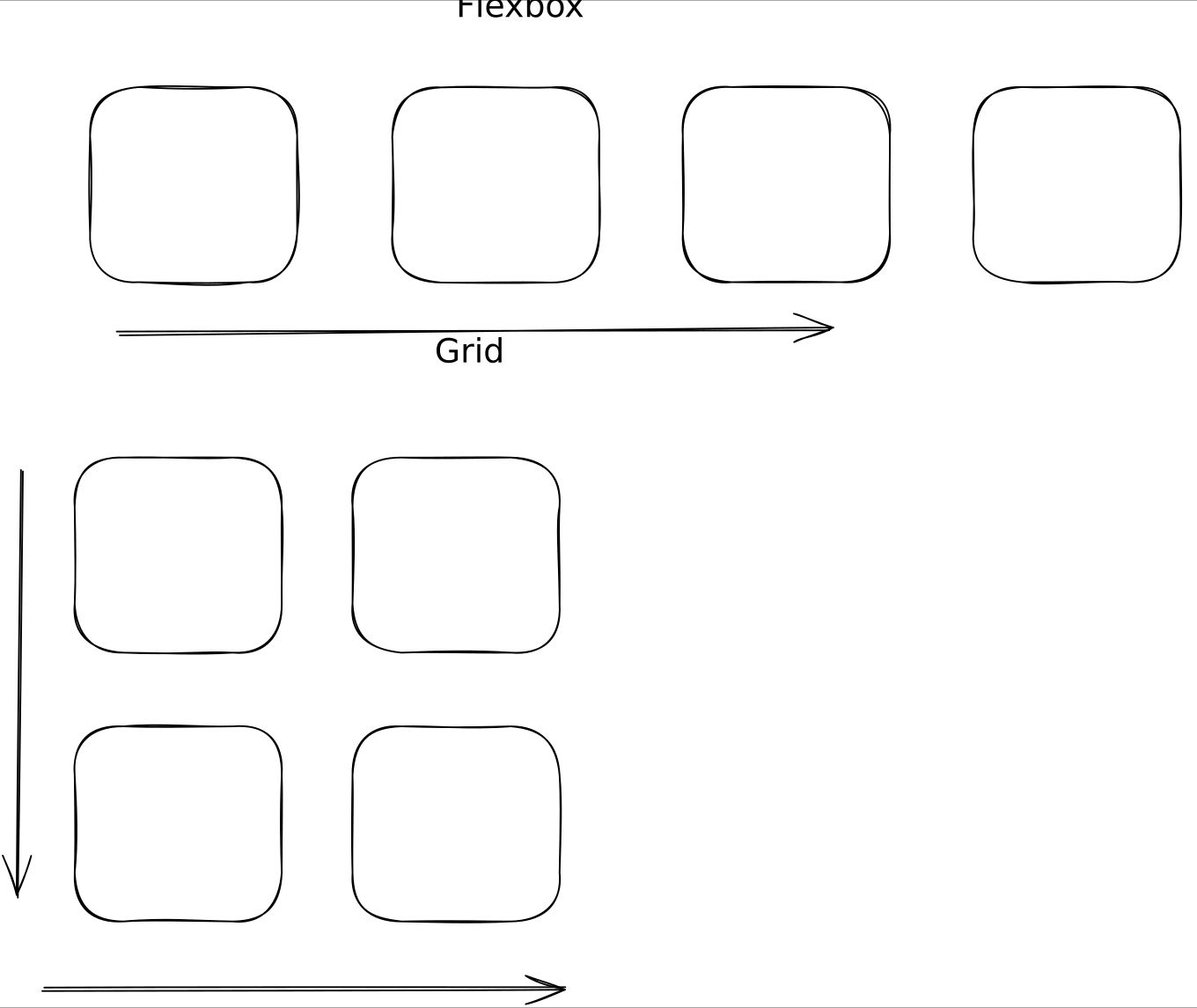
Stąd też osobiście przyjąłem prostą zasadę: grid dla layoutu całej strony (bo pozwala na swobodne myślenie przestrzenne), natomiast flexbox do układania treści w poszczególnych komponentach. Innymi słowy: grida używam do rozmieszczenia nagłówka, głównej treści i stopki strony, podczas gdy zawartość nagłówka ustawiam już przy pomocy flexboxa. Dzięki czemu obydwa systemy layoutowe żyją w pełnej harmonii wewnątrz jednej strony.
Warto też wspomnieć, że obydwa systemy layoutowe, a zwłaszcza grid, pozwalają myśleć proporcjami. Dzięki temu layouty stają się mniej sztywne i w teorii są w stanie lepiej dostosowywać się do możliwości urządzenia osoby użytkowniczej. I to bez potrzeby używania media queries.
Oczywiście nie może być idealnie. Jak wiadomo, z wielką mocą idzie w parze wielka odpowiedzialność. A flexbox i grid są naprawdę potężne. W niektórych miejscach wręcz jakby za potężne. Jednym z takim miejsc jest możliwość zmiany kolejności wyświetlania elementów (np. czwarty element w kodzie będzie wyświetlony jako pierwszy). Taki rozjazd między kolejnością w DOM-ie a na ekranie może powodować problemy z dostępnością. Dodatkowo grid może wymuszać spłaszczenie struktury strony, a tym samym – pozbycie się pewnej warstwy semantyki. Dlatego warto zawsze testować.
Właściwości logiczne
Flexbox niejako przy okazji rozpoczął też zupełnie inną rewolucję, która przeszła niemal niezauważona: odejście od “fizyczności” właściwości CSS-owych.
“Fizyczność”
Co mam na myśli mówiąc o “fizyczności” właściwości CSS-owych? Weźmy sobie za przykład niesamowicie prosty layout, na który składają się dwie kolumny: jedna węższa z nawigacją oraz druga szersza z treścią strony.
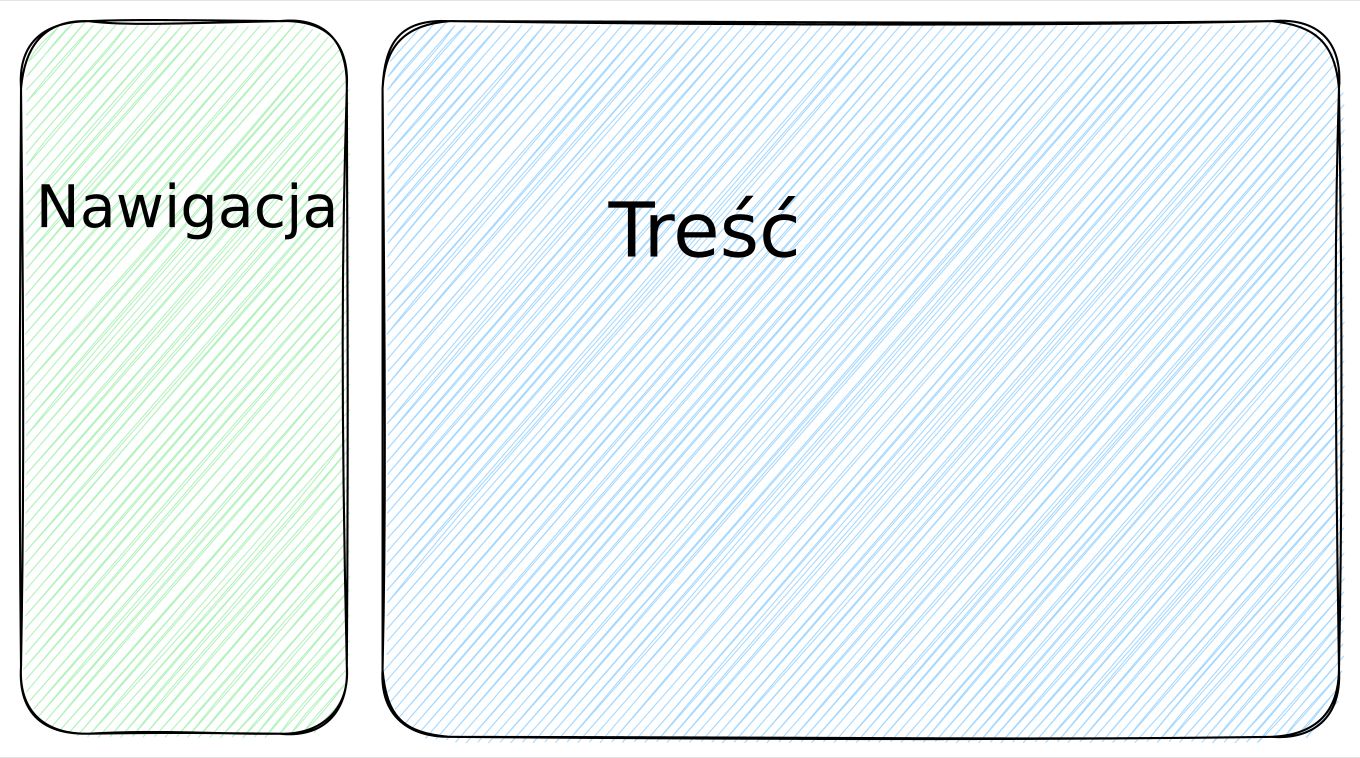
Jeśli chcielibyśmy podejść do problemu “po staremu”, zapewne zastosowalibyśmy float: left dla kolumny z nawigacją i float: right dla kolumny z treścią. Coś mniej więcej w takim stylu:
Jak widać, próba ustawienia czegokolwiek przy pomocy float wymusza na nas myślenie prrzy pomocy określonych kierunków. Coś jest po lewej, a coś po prawej stronie. To nic innego jak odniesienie do kierunków funkcjonujących w realnym, fizycznym świecie. Stąd – “fizyczność” właściwości CSS-owych.
Nie dotyczy to tylko float. Przy pozycjonowaniu używa się wszak właściwości takich jak top, bottom, left i right. Tekst też wyrównujemy do lewej lub prawej. Odniesienia do fizycznych kierunków są w CSS-ie na porządku dziennym.
Problemy z “fizycznością”
Niemniej takie przywiązanie CSS-a do fizycznych kierunków rodzi pewne problemy. Można je podzielić na dwie zasadnicze grupy:
- związane z inkluzywnością,
- związane z layoutem.
Jeśli chodzi o pierwszą grupę, to przywiązanie do konkretnych kierunków przy tworzeniu strony powodować może problemy z internacjonalizacją. Staje się to widoczne zwłaszcza w przypadku stron, które muszą być dostosowane także do języków pisanych od prawej do lewej (RTL), takich jak arabski. Bardzo często bowiem rzeczy, które chcemy mieć po lewej, w rzeczywistości chcemy mieć na początku tekstu. Jeszcze inaczej mówiąc: tam, gdzie osoba używająca naszej strony spojrzy na samym początku. Dobrym przykładem może być logo strony w lewym górnym rogu. To dość popularny wzorzec, stosowany m.in. przez Facebooka:

Niemniej taki układ ma sens tylko na stronach, które tworzone są w językach pisanych od lewej do prawej (LTR). W przypadku języków RTL zdecydowanie przyjaźniejszy dla osób używających aplikacji byłby układ odwrotny. Logo wraz z wyszukiwarką powinno znaleźć się po prawej stronie – czyli tam, gdzie padnie wzrok osoby wchodzącej na stronę. W końcu skoro czyta od prawej do lewej, to nie ma powodu, dla którego miałaby patrzeć na lewą stronę. I dlatego Facebook faktycznie prezentuje odwrócony układ dla np. języka arabskiego:

W przypadku korzystania z “fizycznych” właściwości CSS-a, wszelkie tego typu zmiany trzeba robić ręcznie. A to jest z jednej strony podatne na różne błędy (bo tak naprawdę tworzymy dwie różne wersje layoutu, a więc trzeba testować dwa razy), z drugiej – łatwo przeoczyć jakiś element interfejsu.
Niemniej “fizyczne” właściwości CSS-a są też częściowo niekompatybilne z nowymi sposobami tworzenia layoutów w CSS-ie. Zarówno we flexboksie, jak i gridzie, na próżno szukać jakichkolwiek odwołań do fizycznych kierunków. Nie ma żadnych leftów czy topów, są za to starty i endy. I mieszanie ze sobą tych dwóch sposobów myślenia o CSS-ie niekoniecznie działa tak, jakby można się było tego spodziewać:
Na powyższym przykładzie widać, że gdy przełączymy kierunek tekstu z LTR na pionowy (z góry na dół), to zmienia się jedynie kierunek samego tekstu. Natomiast nie zmieniają się wymiary całego elementu. Bardziej naturalnym efektem byłoby przekręcenie się całych elementów:
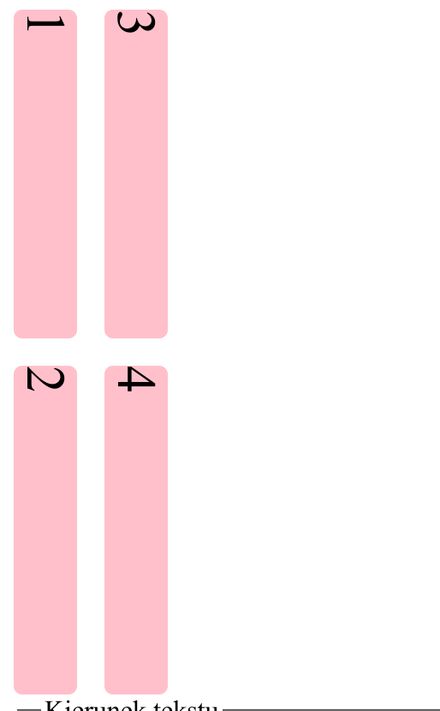
Problem spowodowany jest tym, że grid ustala wymiary w odniesieniu do przepływu tekstu. Natomiast “tradycyjny” CSS robi to niejako na sztywno, w konkretnych kierunkach. W tym przypadku winowajcą jest właściwość width, która określa szerokość elementu. A to oznacza, że zmiana kierunku tekstu nie spowoduje zmiany układu. Ten ma bowiem na sztywno określoną szerokość 400 pikseli i takiej będzie się trzymał.
Logiczne właściwości
I tutaj na scenę wkraczają właściwości logiczne! Czerpią one pełnymi garściami z tego, co wprowadziły systemy layoutowe do CSS-a. Opierają się bowiem na odejściu od przywiązania do fizycznych kierunków na rzecz kierunków ściśle związanych z przepływem tekstu. A tych są tylko dwa:
- blokowy,
- liniowy.
Rachel Andrew dobrze tłumaczy różnicę między nimi. Wyobraźmy sobie przykładowy tekst po polsku, np. fragment inwokacji z Pana Tadeusza. Liniowy kierunek to ten, w którym biegnie tekst w poszczególnych liniach (czyli od lewej do prawej), natomiast blokowy – w którym biegną kolejne linie (czyli od góry do dołu):

Mówiąc jeszcze inaczej: dla tekstu LTR odpowiednikiem width będzie wymiar liniowy, natomiast odpowiednikiem height – wymiar blokowy. Niemniej fakt, że kierunki i wymiary są w logicznych właściwościach powiązane bezpośrednio z tekstem, sprawia, że zmiana jego kierunku zmienia także same wymiary. Wróćmy do naszego przykładu z gridem i zastosujmy właściwość inline-size zamiast width:
Dzięki zastosowaniu właściwości logicznej, nasz grid w całości przystosował się do zmiany kierunku tekstu. Nie tylko sam tekst się przekręcił, ale też cały blok. Wszystko dzięki temu, że zmiana kierunku tekstu zmieniła także same wymiary: nagle liniowy wymiar stał się blokowy i na odwrót. To tak jakby wziąć nasz przykład z inwokacją i po prostu go obrócić na bok:

Powiązanie kierunków z tekstem sprawia, że znika problem niekompatybilności systemów layoutowych z resztą CSS-a. Dodatkowo rozwiązany zostaje problem obsługi języków RTL. Zamiast tworzyć drugą wersję strony, wystarczy zastosować właściwości logiczne, a strona powinna sama się dostosować. Co więcej, można się sprzeczać, czy właściwości logiczne nie ułatwiają nauki CSS-a. W końcu wprowadzają do języka spójność, której od lat brakowało!
Czy jednak warto?
Niemniej jest i łyżka dziegdziu w tej beczce miodu. Właściwości logiczne są dość nowe i wciąż nie wszystko da się zrobić przy ich użyciu. Choć sporo tradycyjnych właściwości i mechanizmów CSS-owych doczekało się już swoich odpowiedników, to wciąż nie wszystkie. Ważnym wyjątkiem są tutaj np. media queries, wciąż ograniczone do width i height zamiast inline-size i block-size. Lata powiązania CSS-a z “fizycznymi” właściwościami sprawiły także, że to one są niejako promowane przez składnię. Widać to zwłaszcza we wszystkich skrótowcach, pokroju właściwości margin. Ustawia ona fizyczne marginesy (margin-top, margin-right, margin-bottom i margin-left), nie zaś ich logiczne odpowiedniki (margin-block-start, margin-block-end, margin-inline-start i margin-inline-end). Zmiana tego stanu rzeczy zapewne zajmie długo, ale taki jest plan.
Mimo tych problemów uważam, że warto wykorzystywać logiczne właściwości i w miarę możliwości zastępować nimi ich “fizyczne” odpowiedniki. Z jednej strony poprawimy dzięki temu inkluzywność naszych stron (choćby dla osób, które postanowią automatycznie przetłumaczyć naszą stronę na jakiś język RTL), z drugiej – najprawdopodobniej ułatwimy sobie pracę z systemami layoutowymi. Najważniejszą zmianą związaną z logicznymi właściwościami jest bowiem przestawienie się na nowy sposób myślenia o layoucie. To już nie jest coś, co ustawiamy na sztywno, ale coś, co jest powiązane z najważniejszą rzeczą na stronie – treścią.
Container queries
Przez lata responsywność była uzyskiwana przy pomocy breakpointów, co było związane m.in. z tym, że z poziomu CSS-a można było reagować jedynie na zmiany rozmiaru całego viewportu. Jednak wraz z popularyzacją frameworków pokroju Reacta czy chociażby wcześniejszych metodyk takich jak BEM zmieniło się też spojrzenie na strony internetowe. Przestały być monolitami, a stały się zbiorem komponentów – często luźno ze sobą powiązanych. Zamiast projektować stronę w całości, można zaprojektować poszczególne klocki, z których się składa, a następnie wykorzystywać je także w innych miejscach. A stąd już tylko krok do design systemów.
Niemniej ta rewolucja odbyła się niejako obok CSS-a. Pojawiły się design systemy, strony zaczęto składać z klocków, a w CSS-ie media queries wciąż uwzględniały tylko wielkość viewportu. Ale to się zmieniło – pojawiły się container queries (zapytania kontenerowe)! W największym skrócie: to takie media queries, ale nie dla całego viewportu, a dla jednego, konkretnego elementu na stronie. Dzięki nim możemy reagować na sytuacje, w których nasze komponenty mają określone wymiary:
W powyższym przykładzie w momencie, gdy szerokość komponentu przekroczy 200 pikseli, tekst w jego wnętrzu stanie się pogrubiony. Przy okazji zastosowałem tam nową składnię dla media i container queries:
@media ( width > 200px ) {}
/* to to samo co */
@media ( min-width: 201px ) {}
Container queries towarzyszą też nowe jednostki, które pozwalają określać wielkości względem rozmiarów kontenera (czyli odpowiedniki jednostek viewportowych, takich jak vw czy vh). Ale jak każda młoda i potężna technologia, container queries mają też swoje problemy. Jednym z nich jest problem z dogadaniem się z responsywnymi obrazkami. Niemniej wierzę, że uda się je w miarę szybko rozwiązać!
Zmienne
Zmienne, a dokładniej niestandardowe właściwości CSS-a, to bez wątpienia jedna z najważniejszych zmian, jakie dotknęły ten język w ostatnich latach. Pozwalają na ponowne wykorzystanie dowolnych wartości w różnych miejscach kodu CSS. Chyba takich sztandarowym przykładem jest przypisanie do zmiennej koloru tekstu, a następnie wykorzystywanie go w innych miejscach:
:root {
--primary-color: black; /* 1 */
}
button {
color: var(--primary-color); /* 2 */
border: 1px var(--primary-color) solid; /* 3 */
}
W powyższym przykładzie stworzyliśmy zmienną --primary-color (1), do której przypisaliśmy kolor czarny. Następnie wykorzystaliśmy tę zmienną do nadania koloru tekstu przycisku (2) oraz koloru jego obramowania (3).
Oczywiście to tylko najprostszy sposób wykorzystania zmiennych. Można je wykorzystać na wiele różnych sposób, np. do przechowywania globalnych i lokalnych ustawień motywu strony, do zarządzania stylami fokusu w różnych elementach czy nawet do stworzenia prostego design systemu. Natomiast fakt, że zmienne są dziedziczone i można je nadpisywać także w media queries, sprawia, że dobrze nadają się też do tworzenia m.in. ciemnego motywu:
:root {
--primary-color: white;
--secondary-color: black;
}
@media (prefers-color-scheme: dark) {
:root {
--primary-color: black;
--secondary-color: white;
}
}
To zresztą tylko ułamek możliwości zmiennych w CSS-ie. W chwili, gdy zacznie się je łączyć z funkcjami trygonometrycznymi i obliczeniami, można tworzyć naprawdę zadziwiające rzeczy. Polecam w tym zakresie twórczość Any Tudor – która faktycznie jest szaloną CSS-ową naukowczynią.
Warstwy
Warstwy kaskady to chyba największa zmiania w zakresie specyficzności CSS-a, jaką pamiętam. Pozwalają one podzielić style na kilka warstw, które będą następnie po kolei aplikowane do elementów na stronie. Co więcej, specyficzność selektorów nie ma znaczenia. Ostatecznie jest aplikowany styl z ostatniej w kolejności warstwy. Spójrzmy na przykład:
W powyższym kodzie na samym początku zadeklarowaliśmy kolejność warstw (1). Najpierw powinna zostać zaaplikowana warstwa reset, a po niej – warstwa theme. W warstwie reset (2) dodaliśmy style dla selektora blockquote.blockquote (3). Określiliśmy w nich, że cytat nie ma używać pochylonego fonta (4). Z kolei w warstwie theme (5) dla selektora .blockquote (6) określiliśmy, że ma używać pochylonego fonta (7). Jeśli porównamy specyficzność obydwu selektorów, zauważymy, że ten z warstwy reset ma wyższą ( 1, 1, 0 vs 0, 1, 0 ). Aplikując zatem “klasyczne” reguły kaskadowości, cytat nie powinien mieć pochyłego tekstu. Jest jednak odwrotnie. Style z warstwy theme nadpisały te z warstwy reset. Nieważna jest specyficzność selektora w warstwie – jeśli “złapie” jakiś element, nadpisze jego style nadane przez poprzednie warstwy.
Tego typu rozwiązanie jest wręcz idealne dla wszelkiego rodzaju normalizacji i resetów, które powinny być bardzo proste w nadpisywaniu. Jeśli taką normalizację/reset przeniesie się do oddzielnej warstwy, nie trzeba się dłużej przejmować selektorami – i tak style zostaną nadpisane. I choć warstwy wymagają zmiany przyzwyczajeń, uważam, że mają naprawdę spory potencjał, by namieszać w sposobie pisania CSS-a.
Zagnieżdżanie stylów
Nie jest to może wielka nowość, ale zdecydowanie przełomowa. Swego czasu była to sztandardowa funkcjonalność wszelkiego rodzaju preprocesorów z Sassem na czele. Często bowiem w CSS-ie zdarza się pisać style dla elementów będących w innych elementach, np. gdy chcemy ostylować akapity znajdująće się w elemencie article. W klasycznym CSS-ie zapisalibyśmy to następująco:
article {
font-size: 1.2em;
}
article p {
color: red;
}
Co prawda czytelność takiego kodu nie jest tragiczna, niemniej brakuje w nim jednego ważnego elementu: wyraźnej relacji między jednym i drugim blokiem deklaracji. Żeby zrozumieć zależność między article i p, trzeba przeczytać cały selektor. W wielu innych językach programowania realizowane jest to przez odpowiednie zagnieżdżanie. Podobnie rozwiązano to w preprocesorach CSS-a. Aż w końcu zawitało to do CSS-a! Powyższy przykład można zapisać obecnie tak:
article {
font-size: 1.2em;
p {
color: red;
}
}
Niemniej to, że możemy zagnieżdżać, niekoniecznie oznacza, że należy zagnieżdżać zawsze i wszędzie. Zwraca na to uwagę Scott Vandehey, przypominając, że zgodnie z najlepszymi praktykami należy dbać o płaską specyficzność CSS-a – zwłaszcza, jeśli stosuje się metodyki pokroju BEM-u. Równocześnie podaje bardzo ciekawe przykłady, gdzie zagnieżdżanie się mocno przydaje – a zatem pseudoklasy, pseudoelementy oraz… media queries. I muszę przyznać, że te ostatnie przekonują mnie najbardziej:
article {
font-size: 1.2em;
@media screen and ( min-width: 60ch ) {
font-size: 1.4em;
}
}
Style “zakresowe”
Wraz z popularyzacją [[web/platform Web Components]] coraz częściej pojawiała się kwestia stylów, które byłyby ograniczone do konkretnej sekcji na stronie. Jasne, można było to zrobić przy wykorzystaniu czy to antycznego iframe, czy bardziej nowoczesnego Shadow DOM, ale obydwa te rozwiązania są zdecydowanie zbyt skomplikowane w momencie, gdy chcemy po prostu ograniczyć style. A i mają swoje problemy związane choćby z dostępnością. Ostatecznie zatem pojawiła się reguła @scope. Jednym z jej zadań jest ograniczenie stylów z elementu style do rodzica, w którym się znajduje:
<div>
<style>
@scope {
p {
color: red;
}
}
</style>
<p>Jestem czerwony</p>
</div>
<div>
<p>Nie jestem czerwony</p>
</div>
Jeśli jednak z jakiegoś powodu nie możemy lub nie chcemy zagnieżdżać elementu style w treści strony, można posłużyć się przekazaniem do @scope selektora, do którego chcemy dane style ograniczyć:
<style>
@scope( .box ) {
p {
color: red;
}
}
</style>
<div class="box">
<p>Jestem czerwony</p>
</div>
<div>
<p>Nie jestem czerwony</p>
</div>
Choć ten drugi przykład na pierwszy rzut oka wygląda bardzo podobnie do istniejącego od zawsze selektora .box p, różni się jedną zasadniczą rzeczą: nie podnosi specyficzności. A to już sprawia, że może stać się ciekawym zamiennikiem w wielu przypadkach.
Nowe systemy kolorów
Nie będę udawał, że jestem ekspertem od spraw kolorów. Jest wręcz odwrotnie – kolory i ja mamy kosę od dość dawna. Aczkolwiek nie mogłem nie zauważyć, że na polu kolorów w CSS-ie zaszły ostatnie naprawdę spore zmiany. Kiedy zaczynałem swoją przygodę z branżą, szczytem możliwości były kolory zapisywane jako liczby heksadecymalne (jak np. #FFFFFF, oznaczająca kolor biały) lub ich angielskie nazwy (wtedy ograniczone do… 16 najpopularniejszych). Dzisiaj często te dwa sposoby uznawane są za przestarzałe. I nic dziwnego, skoro w obecnie jest jakieś 10 nowszych. Bardo dobrze różnice między nimi opisuje Josh W. Comeau. Natomiast w branży powoli zaczyna formować się konsensus, że kolory OKLCH/LCH są najlepszym obecnie sposobem pracy z kolorami w CSS-ie. Jednym z najczęściej wymienianych powodów jest fakt, że zapis ten pozwala na wyrażenie zdecydowanie więcej kolorów niż tradycyjne RGB. Oddam w tej sprawie głos ekspertowi. Dla mnie osobiście kolory OKLCH/LCH są lepsze o tyle, że łatwiej jest je… zgadnąć. W chwili, gdy zmieniam jakieś wartości w tym formacie, mam większe poczucie, że wiem, jaki będzie ostateczny kolor (spoiler: i tak nie wiem).
Ogólnie zmiany w zakresie kolorów mogę podsumować tak: jest tyle nowych zapisów kolorów w CSS-ie, że w sumie nieważne, który się wybierze – i tak będzie lepszy od heksów 🤷.
Animacje połączone z przewijaniem
[!WARNING]
Linki w tej sekcji odsyłają do przykładów, które zawierają animacje oparte na ruchu.
To jedna z tych nowości, które zdecydowanie najlepiej zobaczyć w akcji. Bramus Van Damme przygotował stronę z przykładami. Od strony technicznej opiera się to na nowej właściwości, animation-timeline. Pozwala ona zadeklarować, że nasza animacja ma być zsynchronizowana z przewijaniem strony:
@keyframes grow {
from {
scale: 1;
}
to {
scale: 3; /* 1 */
}
}
.square {
animation: 1ms grow linear; /* 3 */
animation-timeline: scroll( root block ); /* 2 */
}
W powyższym przykładzie dowolny element z klasą .square powiększy się trzykrotnie (1), a animacja ta będzie powiązana z przewijaniem całej strony (2). Natomiast to, jaką animację chcemy odpalić, trzeba tradycyjnie podać we właściwości animation (3).
W składni właściwości animation-timeline pojawiły się dość kryptyczne rzeczy. Na samym początku mamy funkcję scroll() – czyli po prostu oznaczenie, że chodzi nam o przewijanie. Jako argumenty przekazaliśmy root i block. Określenie root oznacza główny element, czyli w tym wypadku będzie to tożsame z całą stroną. Z kolei block to kierunek przewijania określony w terminologii zaczerpniętej z logicznych właściwości. W skrócie: to kierunek, w którym na stronie ułożone są linie tekstu (z góry na dół).
CSS dla internacjonalizacji
Nie zabrakło też w CSS-ie kilku nowinek dla internacjonalizacji. O najważniejszej z nich, czyli właściwościach logicznych, już wspomniałem. Natomiast warto wspomnieć też o innej, zdecydowanie mniej spektakularnej – “myślnikowaniu”. Czyli o możliwości większej kontroli nad tym, jak dzielone i przenoszone są wyrazy w różnych językach do nowej linii. Niemniej ułatwień dla treści w różnych językach jest obecnie więcej. Warto rzucić na nie okiem.
clamp()
Jeszcze jedna nowość zasługuje na wzmiankę: mała funkcja clamp(). Jej działanie może wydawać się zagmatwane, dlatego przygotowałem proste demo:
W powyższym demie czerwona kulka ma ustawioną szerokość na wartość clamp( 16px, 1rem, 32px ). Dzięki zastosowaniu aspect-ratio: 1/1 (innej nowości CSS-owej) jej wysokość zawsze będzie ustawiać się na tę samą wartość. Ale jaka to jest ostatecznie wartość? Otóż clamp() przyjmuje trzy wartości – minimalną, preferowaną oraz maksymalną. Jeśli preferowana wartość znajduje się pomiędzy minimalną a maksymalną, to zostanie użyta. Jeśli jest mniejsza od minimalnej, to zostanie użyta minimalna; jeśli z kolei jest większa od maksymalnej – zostanie użyta maksymalna.
W demie wielkość kulki powiązana jest z wielkością fonta na stronie. W momencie przesuwania suwaka i zwiększania wielkości fonta na stronie, można zauważyć, że jeśli wielkość fonta przekroczy 32 piksele, to kulka i tak nie powiększy się ponad ten rozmiar. Tak samo jeśli zmniejszymy rozmiar fonta poniżej 16 pikseli, kulka nie będzie miała mniej. Natomiast jeśli ustawimy suwak na np. 25, to kulka też będzie miała 25 pikseli.
Dzięki tym właściwościom clamp() można wykorzystać m.in. do responsywnej typografii (w ktorej wielkość fonta jest uzależniona od wielkości viewportu, ale wypadałoby zadbać o to, żeby nie była za mała lub za duża) czy zastąpić część media queries.
Czego brakuje?
Jest dobrze, ale wciąż nie jest idealnie! Co prawda lista brakujących acz niezbędnych do życia ficzerów stała się zdecydowanie krótsza ostatnimi czasy, lecz wciąż jest na niej kilka pozycji. Osobiście najbardziej brakuje mi dwóch rzeczy:
- pełnego wsparcia dla logicznych właściwości,
- sensownego systemu modułów.
O logicznych właściwościach już wspominałem, pora zatem wspomnieć o systemie modułów. Otóż w świecie, w którym dominują biblioteki pokroju Reacta, myślenie o stronach jako o zbiorach komponentów wydaje się dość naturalne. Co więcej, tego typu podział przenosi się z kodu także na pliki. Zamiast trzymać komponent nagłówka i stopki w jednym pliku, zazwyczaj rozbija się to na dwa pliki: jeden dla nagłówka, drugi dla stopki. Zdecydowanie poprawia to czytelność kodu i pozwala szybciej się w nim odnaleźć. To, co w świecie JS stało się już normą (a wręcz standardem), w świecie CSS wciąż jeszcze tak naprawdę nie zaistniało.
Owszem, istnieje stareńki @import, który pozwala nawet wczytywać arkusze stylów warunkowo (np. gdy zostanie spełnione jakieś media query). Niemniej od lat ma on poważne problemy z wydajnością i nic nie wskazuje na to, żeby miało się to zmienić. W momencie, gdy stosuje się @import w plikach CSS, przeglądarka musi najpierw wczytać arkusz zawierający regułę @import, a dopiero potem – kolejne arkusze. Element link[rel=stylesheet] w HTML-u nie ma tego problemu – arkusze są wczytywane równolegle:
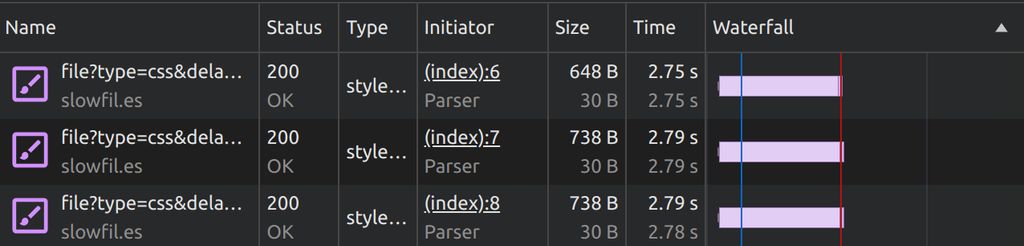
W teorii ten problem da się obejść prosto: przerzucając reguły @import do elementu style wewnątrz pliku HTML. Ale jak zauważył Harry Roberts, to było (lub nawet wciąż jest) zabugowane. W połączeniu z istniejącymi od prawieków dobrymi praktykami każącymi unikać @import, obawiam się, że ten okręt już odpłynął. A szkoda, bo dobry system modułów w CSS-ie to chyba największa bolączka, jaka została do rozwiązania. I boli to tym bardziej, że to rozwiązanie już tu jest – po prostu nikt go nie chce używać.
Przyszłość: deklaratywny design?
Nie mam żadnych wątpliwości, że CSS będzie się dalej dynamicznie rozwijał i dodawał coraz więczej ficzerów, których potrzebują i chcą osoby webdeveloperskie. Równocześnie mam nieodparte wrażenie, że kolejna wielka rewolucja będzie związana nie z przełomem technologicznym, a światopoglądowym. W końcu obecne możliwości CSS-a wpływają bezpośrednio na to, jak wygląda responsywność, ale też – jakie są limity designu. I coraz częściej pojawiają się głosy, że być może nadszedł czas na osoby inżynierskie designu. Z jednej strony związane jest to z tym, jak bardzo skompikował się cały proces od momentu stworzenia pierwszego szkicu projektu aż do jego faktycznego wdrożenia. Z drugiej jednak strony – coraz głośniej mówi się też o deklaratywnym designie. Jak to ujął Jeremy Keith:
[ …] focus on creating the right inputs rather than trying to control every possible output. Leave the final calculations for those outputs to the browser—that’s what computers are good at.
[[…] skupić się na tworzeniu odpowiednich danych wejściowych, zamiast próbować kontrolować każdy możliwy wynik. Pozostawmy ostateczne obliczenia tych wyników przeglądarce – w końcu to to, w czym komputery są dobre.]
To niejako przedłużenie idei, którą Jen Simmons przedstawiła w Intrinsic Web Design: korzystajmy z nowoczesnych dobrodziejstw CSS-a i pozwalajmy przeglądarce robić jak najwięcej za nas. Bo w końcu mamy flexboksa i grida, które pozwalają nam myśleć proporcjami i relacjami między poszczególnymi elementami strony. Nie musimy już więcej myśleć o tym, ile dokładnie pikseli powinien mieć dany komponent. Ba, na dobrą sprawę nie powinniśmy nawet o tym myśleć – bo ostatecznie nie wiemy, w jakich warunkach wyświetlona zostanie strona. Przeglądarka wie najlepiej, na co może sobie pozwolić. A skoro ona to wie, to być może najlepszym pomysłem jest danie jej pracować w spokoju.
Przerzucenie sporej części pracy na przeglądarkę to też tak naprawdę krok w stronę lepszego dostosowania strony WWW do preferencji osoby użytkowniczej. Dobrym przykładem może być tutaj odejście od ustalania bazowej wielkości fonta i zamiast tego posługiwanie się jednostkami rem i em, by skalować treść względem wielkości fonta ustawionej w przeglądarce. Dzięki temu z jednej strony przerzucimy sporą część pracy na przeglądarkę, bo po prostu określimy jej relacje pomiędzy wielkością naszej treści a jej wielkością fonta, z drugiej zaś – będziemy respektować ustawienia osoby użytkowniczej, która mógła zmienić domyślną wielkość fonta w przeglądarce.
Deklaratywny design to doprowadzenie idei responsywności do ekstremum. U jego podstaw leży bowiem oddawanie sporej części kontroli nad designem przeglądarce (i tym samym, pośrednio, osobie użytkowniczej). To sprawia, że nasza strona nie będzie wyglądać wszędzie tak samo, ale będzie się jak najlepiej dostosowywać do urządzenia osoby użytkowniczej. I choć brzmi to jak mocno utopijna wizja, to chcę wierzyć, że właśnie taka czeka nas przyszłość CSS-a i responsywności.
Źródła
- Geoff Graham, Writing CSS In 2023: Is It Any Different Than A Few Years Ago?, (data dostępu: ), w: Smashing Magazine, (data dostępu: ).
- Bill Merikallio, Adam Pratt, Kornel Lesiński, Dlaczego układ na tabelkach jest głupi: opis problemu i jego rozwiązania, (data dostępu: ).
- Una Kravets, Ten modern layouts in one line of CSS, (data dostępu: ), w: web.dev, (data dostępu: ).
- Heydon Pickering, Making Future Interfaces: Algorithmic Layouts, (data uploadu: , data dostępu: ), w: YouTube, (data dostępu: ).
- Chris Coyier, The Holy Grail Layout with CSS Grid, (data dostępu: ), w: CSS Tricks, (data dostępu: ).
- Joshua Comeau, An Interactive Guide to Flexbox in CSS, (data dostępu: ), w: Joshua Comeau, Josh W Comeau, (data dostępu: ).
- Joshua Comeau, An Interactive Guide to CSS Grid, (data dostępu: ), w: Joshua Comeau, Josh W Comeau, (data dostępu: ).
- Robin Rendle, Does CSS Grid Replace Flexbox?, (data dostępu: ), w: CSS Tricks, (data dostępu: ).
- Ahmad Shadeed, Grid for layout, Flexbox for components, (data dostępu: ), w: Ahmad Shadeed, Ahmad Shadeed, (data dostępu: ).
- Violet Peña, Using CSS Grid the right way, (data dostępu: ), w: Violet Peña, hey it's violet, (data dostępu: ).
- Andy Bell, Create a responsive grid layout with no media queries, using CSS Grid, (data dostępu: ), w: Andy Bell, Piccalilli, (data dostępu: ).
- Rachel Andrew, Grid, content re-ordering and accessibility, (data dostępu: ), w: Rachel Andrew, Rachel Andrew, (data dostępu: ).
- Manuel Matuzović, The Dark Side of the Grid (Part 1), (data dostępu: ), w: Manuel Matuzović, Manuel Matuzović, (data dostępu: ).
- Ahmad Shadeed, Right-to-left Styling, (data dostępu: ).
- Rachel Andrew, Understanding Logical Properties And Values, (data dostępu: ), w: Smashing Magazine, (data dostępu: ).
- David Bushell, Changing CSS for Good, (data dostępu: ), w: David Bushell, David Bushell, (data dostępu: ).
- Chris Coyier, Do Logical Properties Make CSS Easier to Learn?, (data dostępu: ), w: Chris Coyier, Chris Coyier, (data dostępu: ).
- Jeremy Keith, Let’s get logical, (data dostępu: ), w: Jeremy Keith, Adactio, (data dostępu: ).
- Miriam Eric Suzanne, A long-term plan for logical properties?, (data dostępu: ), w: Miriam Eric Suzanne, Miriam Eric Suzanne, (data dostępu: ).
- Dan Rose, Seeing the Pages For the Components | adjacent, (data dostępu: ), w: adjacent, (data dostępu: ).
- Ahmad Shadeed, Say Hello To CSS Container Queries, (data dostępu: ), w: Ahmad Shadeed, Ahmad Shadeed, (data dostępu: ).
- Stephanie Eckles, Container Query Units and Fluid Typography, (data dostępu: ), w: Stephanie Eckles, Modern CSS Solutions, (data dostępu: ).
- Jason Grigsby, On Container Queries, Responsive Images, and JPEG-XL, (data dostępu: ), w: Cloud Four, (data dostępu: ).
- Using CSS custom properties (variables) - CSS: Cascading Style Sheets, (data dostępu: ), w: MDN, (data dostępu: ).
- Sara Soueidan, Global and Component Style Settings with CSS Variables, (data dostępu: ), w: Sara Soueidan, Sara Soueidan, (data dostępu: ).
- Stephanie Eckles, Standardizing Focus Styles With CSS Custom Properties, (data dostępu: ), w: CSS Tricks, (data dostępu: ).
- Brecht De Ruyte, Creating A High-Contrast Design System With CSS Custom Properties, (data dostępu: ), w: Smashing Magazine, (data dostępu: ).
- Ana Tudor, Ana Tudor, (data dostępu: ), w: YouTube, (data dostępu: ).
- Cascade layers, (data dostępu: ), w: MDN, (data dostępu: ).
- Manuel Matuzović, Cascade Layers are useless*, (data dostępu: ), w: Manuel Matuzović, Manuel Matuzović, (data dostępu: ).
- Using CSS nesting - CSS: Cascading Style Sheets, (data dostępu: ), w: MDN, (data dostępu: ).
- Scott Vandehey, When to Nest CSS, (data dostępu: ), w: Cloud Four, (data dostępu: ).
- Keith J. Grant, Scoped CSS is Back, (data dostępu: ), w: Keith J. Grant, Keith J. Grant, (data dostępu: ).
- Chris Coyier, Style Scoped, (data dostępu: ), w: Chris Coyier, Chris Coyier, (data dostępu: ).
- Joshua Comeau, Color Formats in CSS - hex, rgb, hsl, lab, (data dostępu: ), w: Joshua Comeau, Josh W Comeau, (data dostępu: ).
- Andrey Sitnik, Travis Turner, OKLCH in CSS: why we moved from RGB and HSL, (data dostępu: ), w: Martian Chronicles, (data dostępu: ).
- Chris Lilley, What are color gamuts, (data dostępu: ), w: Chris Lilley, Chris Lilley, (data dostępu: ).
- Bramus Van Damme, Scroll-driven Animations, (data dostępu: ).
- animation-timeline - CSS: Cascading Style Sheets, (data dostępu: ), w: MDN, (data dostępu: ).
- Richard Rutter, All you need to know about hyphenation in CSS | Clagnut by Richard Rutter, (data dostępu: ), w: Richard Rutter, Clagnut, (data dostępu: ).
- Chen Hui Jing, CSS for internationalisation, (data dostępu: ), w: Chen Hui Jing, Chen Hui Jing, (data dostępu: ).
- clamp() - CSS: Cascading Style Sheets, (data dostępu: ), w: MDN, (data dostępu: ).
- aspect-ratio - CSS: Cascading Style Sheets, (data dostępu: ), w: MDN, (data dostępu: ).
- Ruslan Yevych, Fluid Sizing Instead Of Multiple Media Queries?, (data dostępu: ), w: Smashing Magazine, (data dostępu: ).
- @import - CSS: Cascading Style Sheets, (data dostępu: ), w: MDN, (data dostępu: ).
- Harry Roberts, CSS and Network Performance, (data dostępu: ), w: Harry Roberts, CSS Wizardry, (data dostępu: ).
- Steve Souders, don’t use @import, (data dostępu: ), w: Steve Souders, High Performance Web Sites, (data dostępu: ).
- Jim Nielsen, The Case for Design Engineers, (data dostępu: ), w: Jim Nielsen, Jim Nielsen’s Blog, (data dostępu: ).
- Jeremy Keith, Declarative design, (data dostępu: ), w: Clearleft, (data dostępu: ).
- Andy Bell, Be the browser’s mentor, not its micromanager. - Build Excellent Websites, (data dostępu: ).
Dodatkowe materiały
- Jen Simmons, Web Design Experiments by Jen Simmons, (data dostępu: ).
- Heydon Pickering, Andy Bell, Relearn CSS layout: Every Layout, (data dostępu: ).
- Andy Bell, Managing Flow and Rhythm with CSS Custom Properties, (data dostępu: ), w: 24 ways, (data dostępu: ).
- Layout patterns, (data dostępu: ), w: web.dev, (data dostępu: ).
- Joshua Comeau, Understanding Layout Algorithms, (data dostępu: ), w: Joshua Comeau, Josh W Comeau, (data dostępu: ).
- Heydon Pickering, Algorithmic layouts, (data dostępu: ), w: Gist, (data dostępu: ).
- Una Kravets, 1-Line Layouts, (data dostępu: ).
- Anna, How to finally understand CSS flexbox, (data dostępu: ), w: DEV Community, (data dostępu: ).
- Dave Geddes, Article Layout with CSS Grid, (data dostępu: ), w: Dave Geddes, mastery.games, (data dostępu: ).
- Rachel Andrew, Editorial Design Patterns With CSS Grid And Named Columns, (data dostępu: ), w: Smashing Magazine, (data dostępu: ).
- Chris Coyier, Quick! What's the Difference Between Flexbox and Grid?, (data dostępu: ), w: CSS Tricks, (data dostępu: ).
- Rachel Andrew, Should I use Grid or Flexbox?, (data dostępu: ), w: Rachel Andrew, Rachel Andrew, (data dostępu: ).
- koduje, Współczesny responsive web design: jak tworzyć rensponsywne strony?, (data uploadu: , data dostępu: ), w: YouTube, (data dostępu: ).
- Jeremy Keith, Making Things Better: Redefining the Technical Possibilities of CSS by Rachel Andrew, (data dostępu: ), w: Jeremy Keith, Adactio, (data dostępu: ).
- Ahmad Shadeed, Case Study: Rebuilding TechCrunch layout with modern CSS, (data dostępu: ), w: Ahmad Shadeed, Ahmad Shadeed, (data dostępu: ).
- Lea Verou, LCH colors in CSS: what, why, and how?, (data dostępu: ), w: Lea Verou, Lea Verou, (data dostępu: ).
- Una Kravets, Bramus, Adam Argyle, CSS Wrapped: 2023!, (data dostępu: ), w: Chrome for Developers Blog, (data dostępu: ).
- Una Kravets, The new responsive: Web design in a component-driven world, (data dostępu: ), w: web.dev, (data dostępu: ).
- Adrian Bece, CSS Container Queries: Use-Cases And Migration Strategies, (data dostępu: ), w: CSS Tricks, (data dostępu: ).
- Web Conferences Amsterdam, CSS Containers, What Do They Know? | Miriam Suzanne | CSS Day 2023, (data uploadu: , data dostępu: ), w: YouTube, (data dostępu: ).
- Basic concepts of logical properties and values - CSS: Cascading Style Sheets, (data dostępu: ), w: MDN, (data dostępu: ).
- Andy Bell, Rachel Andrew, Una Kravets, Adam Argyle, Emma Twersky, Camden Bickel, Kevin Lozandier, Rob Dodson, Jiwoong Lee, Ewa Gasperowicz, Kayce Basques, Learn CSS, (data dostępu: ), w: web.dev, (data dostępu: ).
- Hey! Presents, Andy Bell – Be the browser’s mentor, not its micromanager, (data uploadu: , data dostępu: ), w: YouTube, (data dostępu: ).
- Jeremy Keith, Declarative design systems, (data dostępu: ), w: Clearleft, (data dostępu: ).
- Ahmad Shadeed, Rebuilding a comment component with modern CSS, (data dostępu: ), w: Ahmad Shadeed, Ahmad Shadeed, (data dostępu: ).
- Chris Coyier, Modern CSS in Real Life, (data dostępu: ), w: Chris Coyier, Chris Coyier, (data dostępu: ).
- Stephanie Eckles, Modern CSS For Dynamic Component-Based Architecture, (data dostępu: ), w: Stephanie Eckles, Modern CSS Solutions, (data dostępu: ).
- beyond tellerand, Jeremy Keith – Declarative Design – SOTR, (data uploadu: , data dostępu: ), w: YouTube, (data dostępu: ).
- Manuel Matuzović, The Dark Side of the Grid (Part 2), (data dostępu: ), w: Manuel Matuzović, Manuel Matuzović, (data dostępu: ).